迷失高维空间:向量数据库索引技术
12 / 19 / 2024 | 最后修改于 12 / 19 / 2024
简略介绍两类向量数据库索引技术
引言
向量数据库 (Vector Database) 是一种专门用于存储和查询向量数据的数据库。向量数据库的应用场景非常广泛,例如:相似图片搜索、相似商品推荐、人脸识别、语音识别、文本相似度计算等。前两年 LLM 等大型模型的兴起,也使得向量数据库爆火了一把,各种初创公司纷纷推出了各种向量数据库产品,传统数据库也纷纷推出了向量数据的支持。
在这些应用场景中,我们需要高效地存储和查询大量的向量数据,以便快速地找到相似的向量。为了实现高效的向量查询,我们需要设计高效的向量索引技术。
向量?能吃吗?
在介绍向量数据库索引技术之前,我们先来了解一下什么是向量。在数学中,向量是一个有方向和大小的量,通常用一个有序数组来表示。例如,二维空间中的一个向量可以表示为 ,三维空间中的一个向量可以表示为 ,以此类推。在计算机科学中,向量通常用一个数组来表示,例如:。
向量能用来干什么呢?在机器学习和数据挖掘中,我们通常使用向量来表示数据,例如:图片、商品、人脸、语音、文本等。原始数据通过一些特定的特征提取算法/模型,可以转换为一个向量。在提取的过程中,这些向量通常被赋予了语义,相似的数据在向量空间中也是相近的。
比如我们将两张猫的图片通过特征提取算法转换为两个向量,同时将一张狗的图片也转换为一个向量。在向量空间中,两张猫的图片的向量应该是相近的,而狗的图片的向量应该是远离猫的图片的向量的。
通过计算向量之间的相似度/距离,我们可以找到相似的数据,从而实现各种应用场景。
向量数据库要做什么
向量数据库的主要功能是存储和查询向量数据。在存储方面,向量数据库需要高效地存储大量的向量数据。在查询方面,向量数据库需要高效地查询相似的向量数据。不像传统数据库,向量数据库的查询是基于向量之间的相似度/距离的,而不是基于精确匹配的,一次查询给出一个目标向量,数据库返回距离目标向量最近的 个向量。
存储略过不表,我们主要关注查询。一次最朴素的查询方法是暴力搜索,即计算目标向量与数据库中每个向量之间的距离,然后返回距离最近的 个向量。这种方法的时间复杂度是 ,其中 是数据库中向量的数量。当数据库中的向量数量很大时,这种方法的查询效率是非常低的。在实践中不可接受。
帮帮我,索引先生:向量索引技术
类似传统数据库的索引技术,向量数据库也需要设计高效的索引技术来加速查询。虽然都叫索引,但内部结构和实现方式是完全不同的。这里简单介绍两种应用广泛的向量索引技术:基于聚类的索引和基于图的索引。
基于聚类的索引
基于聚类的索引是一种将向量数据划分为多个簇 (Cluster) 的索引技术。 实践中通常与量化算法结合使用,这里略去量化相关的细节。
基于聚类的索引的基本思想是:将向量数据划分为多个簇,每个簇包含多个向量,簇内的向量基本都是相似的。一个可能的聚类结果如图:
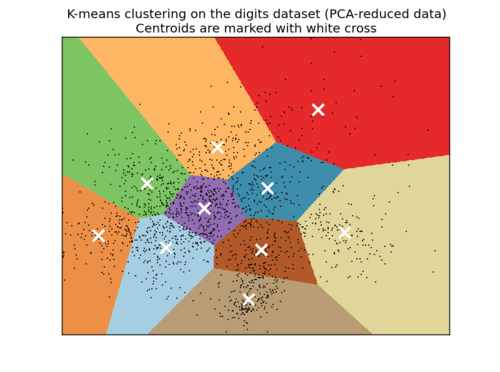
每一个簇都有一个代表向量,通常是簇内所有向量的平均值。在查询时,首先比较所有簇的代表向量,找到距目标向量最近的簇,然后只计算目标向量与簇中的向量之间的距离,最后返回距离最近的 个向量。
经过聚类的处理,查询时只需要计算目标向量与代表向量的距离,再计算与簇内向量之间的距离,大大减少了计算量,提高了查询效率。
基于图的索引
基于图的索引是一种将向量数据构建成图结构的索引技术。其中最具代表性的算法是 HNSW (Hierarchical Navigable Small World)。
HNSW = Hierarchical + NSW,首先了解一下 NSW。
NSW图中,每个节点都会与邻近的节点相连,组成一张完整的NSW图。创建过程的例子如图:
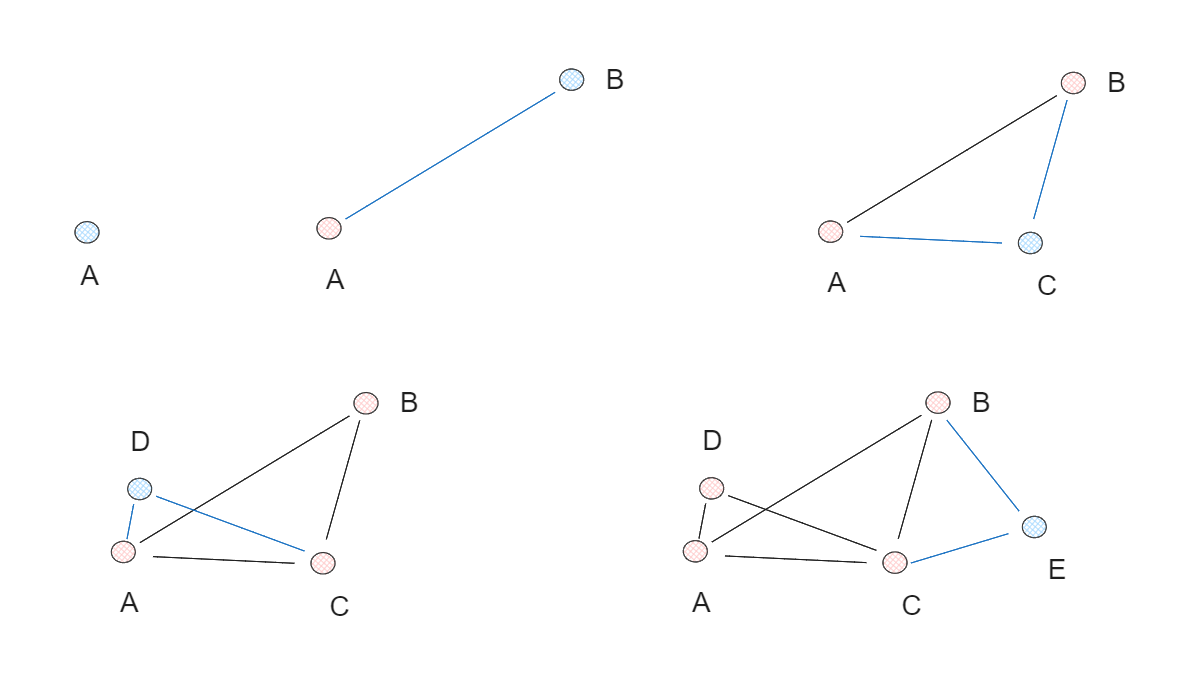
其检索的底层逻辑是贪心算法,从任意节点开始,检索起相邻节点中与其更加相似的节点,然后转移到该节点,过程循环往复,直到找到局部最小值,即当前节点比任何邻居节点都更接近查询向量,此时停止搜索。
NSW 的检索范围进一步缩小,理论上现在只要经过一条路径就能找到最近邻,但是途中的跳数可能仍然很多,这时候引入了 HNSW。
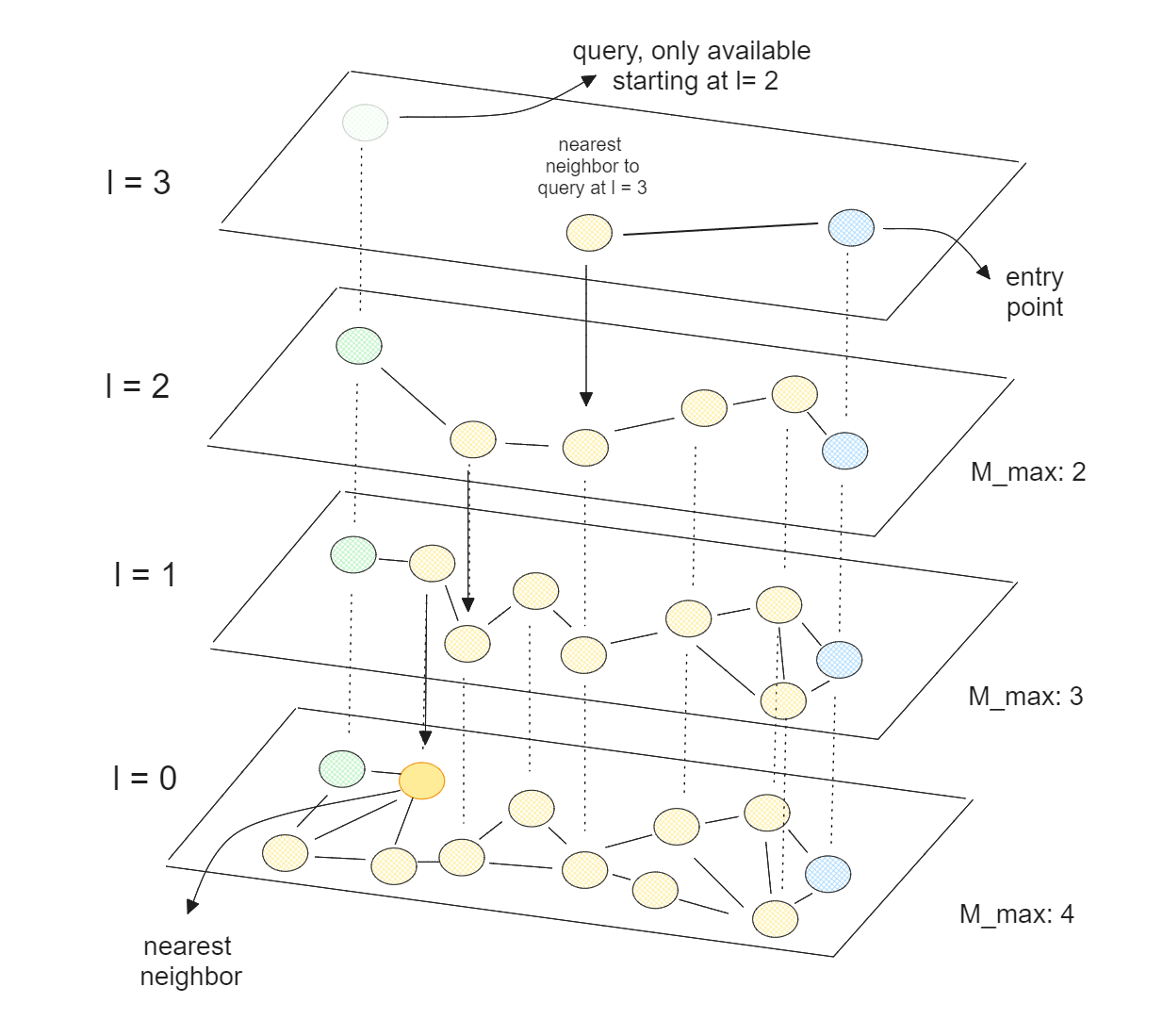
HNSW 是在 NSW 的基础上引入了层级结构,通过构建多层的 NSW 图,每一层的节点都是下一层节点以指数级概率缩减得到的,每次查询从最高层开始,逐渐进入下一层,直到找到最近邻。在高层的 NSW 图中,节点的数量较少,每一跳期望可以移动更远的距离,从而减少检索的跳数。
结语
向量数据库像是数据界的“指南针”,在高维空间里帮我们找到方向。无论是聚类的“抱团取暖”,还是图索引的“跳跃寻邻”,都在尽力加速相似性搜索。未来,随着硬件加持和算法升级,它会越来越强大。迷失高维?别慌,向量数据库正带着“神兵利器”来拯救我们!